
日志管理器
我们已经认识到,为了提高性能,数据库将数据存储在内存缓冲区中。但是,如果在事务提交时,服务器崩溃,你就会丢失所有内存中的数据,这将导致事务持久性问题。
你可以将所有数据写入磁盘,但是,如果服务器崩溃,你可能只写入一半数据,这会导致事务的原子性问题。
事务所做的任何修改写入必须要全部撤销或全部写入。
为解决这一问题,有两种解决方案:
- 影子拷贝/页:每一个事务创建自己的数据库拷贝(或者是数据库的一部分),在这个拷贝上面工作。如果发生了错误,移除该拷贝;如果成功,数据库立刻将数据通过文件系统技巧从拷贝切换,并移除“旧的”数据。
- 事务日志:事务日志是一段存储空间。在每个写入磁盘操作之前,数据库将信息写入事务日志,以便在事务崩溃/撤销时,数据库能够知道如何移除(或完成)未完成的事务。
WAL
当大型数据库需要很多事务时,影子拷贝/页会占用大量磁盘空间。这就是现代数据库使用事务日志的原因。事务日志必须存储在稳定的存储中。我不会深入介绍存储技术,只简单提一句,使用(至少)RAID 磁盘阵列能够有效防止磁盘失败。
很多数据库(包括 Oracle、SQL Server、DB2、PostgreSQL、MySQL 和 SQLite)使用预写式日志(Write-Ahead Logging protocol,WAL)。WAL 包括三个规则:
- 1) 数据库每一条修改都要产生一条日志记录,这个日志记录必须在数据写入磁盘之前先写入事务日志
- 2) 日志记录必须按照顺序写入:如果日志记录 A 发生在日志记录 B 之前,那么 A 必须在 B 之前写入
- 3) 当事务提交时,直到事务成功结束,提交顺序必须写入事务日志
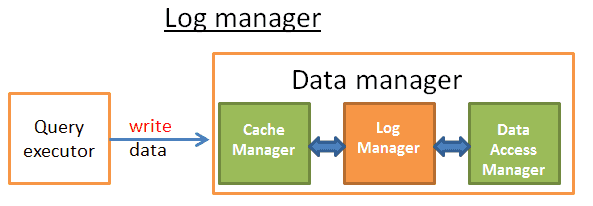
这个工作是由日志管理器完成的。简单来说,日志管理器就是,在缓存管理器和数据访问管理器(数据访问管理器将数据写入磁盘)之间,在数据写入磁盘之前,将每一个更新/删除/创建/提交/回滚写入事务日志。很简单,是不是?
不对!经过这么多的学习,你应该知道,关于数据库的一切都可能引起“数据库效应”。严肃地说,日志管理器的问题是,找到一种既能写入日志,又能保持好性能的方式。如果写入事务日志太慢,它就会拖慢所有事情。
ARIES
1992 年,IBM 的研究者“发明了”一种改进版本的 WAL,称为 ARIES。ARIES 多多少少被大多数现代数据库使用。具体逻辑可能不一样,但是 ARIES 背后的概念已经被广泛使用。我给发明这个词加了引号,是因为根据 MIT 课程,IBM 研究者“什么都没干,只是写了篇事务恢复的最佳实践”。因为 ARIES 论文发表的时候,我只有 5 岁,我不关心那些尖酸刻薄的研究者们的流言蜚语。事实上,我之所以在这里写出来这个,主要是为了在我们开始最后一个技术部分之前稍微休息一下。我阅读了大量关于 ARIES 的研究论文,发现它的确很有趣!在这部分我只介绍 ARIES 的大概,但是如果你想学习点真正的知识的话,我强烈推荐你去阅读这些论文。
ARIES 是 Algorithms for Recovery and Isolation Exploiting Semantics(利用语义的恢复和隔离算法)的缩写。
这项技术的目的有两个:
- 1) 获得写日志的良好性能
- 2) 获得快速可靠的恢复
数据库之所以要回滚事务,其原因是多方面的:
- 因为用户取消了事务
- 因为服务器或网络失败
- 因为事务打破了数据库完整性(例如,你有一个带有 UNIQUE 约束的列,而事务视图插入重复值)
- 因为死锁
有时(比如网络失败)数据库能够从事务恢复。
这是怎么做到的?为回答这个问题,我们需要理解存储在日志记录中的信息。
日志
每一个事务中的操作(增加/删除/修改)都会产生一条日志。这个日志记录包括:
- LSN:Log Sequence Number(日志顺序数)。LSN 按照顺序以此给出*。这意味着如果一个操作 A 发生在操作 B 之前,那么日志 A 的 LSN 就会比 日志 B 的 LSN 小。
- TransID:产生操作的事务 ID。
- PageID:被修改的数据在磁盘的位置。磁盘上数据的最小值是页,因此数据的位置也就是包含了数据的页的位置。
- PrevLSN:同一事务产生的前一个日志记录的链接。
- UNDO:移除该操作影响的方法。例如,如果操作是更新,UNDO 会保存元素被更新之前的值/状态(物理 UNDO)或者回到之前状态的撤销操作(逻辑 UNDO)**。
- REDO:重现操作的方法。类似地,有两种方法保存 REDO:保存操作之后元素的值/状态或者可以重复执行的操作本身。
- …:(顺便说一句,ARIES 日志还有另外两个字段:UndoNxtLSN 和 Type)。
另外,磁盘上每一个页(保存数据的页,不是保存日志的页)都保存有最后修改数据的那个操作的日志记录 ID(LSN)。
*这种给出 LSN 的方式更复杂一些,因为它与保存日志的方式相关。但思路是一致的。
**ARIES 只使用逻辑 UNDO,因为物理 UNDO 会有很大的消耗。
注意:就我所知,只有 PostgreSQL 没有使用 UNDO,而是使用了一个垃圾回收守护进程来移除旧的数据。这与 PostgreSQL 使用的数据版本实现相关。
为了更好理解,下面是日志记录的简单的图形化例子。这个日志记录来自于查询 “UPDATE FROM PERSON SET AGE = 18;”。假设该查询在事务 18 中执行。
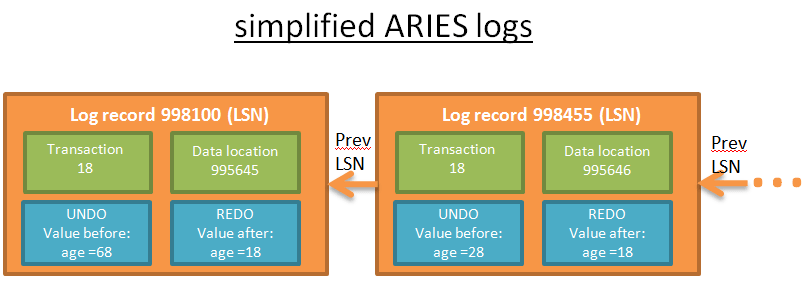
每个日志都有唯一的 LSN。同一事务的日志被链接到一起。日志是顺序相连的(链表中的最后一个日志对应着最后一个操作)。
日志缓冲
为避免写入日志带来的主要瓶颈,数据库会使用日志缓冲。
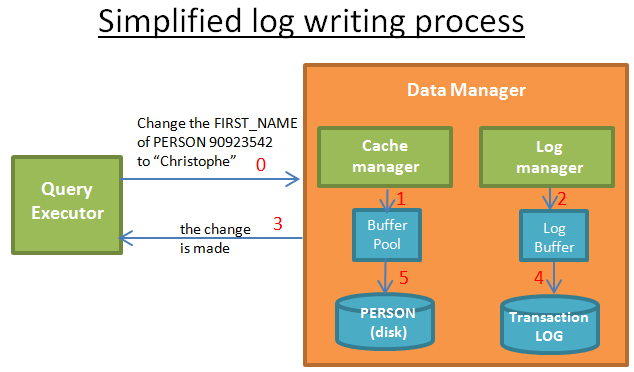
当查询执行器请求修改时:
- 1) 缓存管理器在其缓冲区保存修改
- 2) 日志管理器在其缓冲区保存相关日志
- 3) 在这一步,查询执行器认为操作已经完成(因此开始请求另外的修改)
- 4) 然后(之后),日志管理器在事务日志写入日志。何时写入日志是由算法决定的。
- 5) 然后(之后),缓存管理器将修改写入磁盘。何时写入数据是由算法决定的。
事务提交,意味着事务中的每一个操作,上述 1,2,3,4,5 步已经完成。写入事务日志是很快的,因为这仅仅是“在事务日志某个地方加入一条记录”;但是,将数据写入磁盘就复杂得多,因为“需要按照能够快速读取的方式写入数据”。
STEAL 和 FORCE 策略
由于性能原因,第 5 步可能会在事务提交之后完成,因为如果万一崩溃,还有机会按照 REDO 日志。这被称为 NO-FORCE 策略。
数据库也可以选择 FORCE 策略(也就是说,第 5 步必须在提交之前完成)降低恢复期间的工作负载。
另一个问题是,数据是一步一步写入磁盘的(STEAL 策略)还是缓冲管理器需要等待提交命令,一次性写入(NO-STEAL 策略)。STEAL 和 NO-STEAL 的选择取决于你想要什么:使用 UNDO 日志快速写入很长的恢复,还是快速恢复?
下面是恢复策略的影响总结:
- STEAL/NO-FORCE 需要 UNDO 和 REDO:最高性能,但是更复杂的日志和恢复过程(例如 ARIES)。这是大多数数据库的选择。注意,我通过很多研究论文和课程了解到这个事实,但是我没有在官方文档找到(显式的)证据。
- STEAL/ FORCE 只需要 UNDO。
- NO-STEAL/NO-FORCE 只需要 REDO。
- NO-STEAL/FORCE 不需要任何东西:最坏性能,需要大量冗余。
恢复
好了,现在我们有了漂亮的日志,用用它们吧!
假设我们新来的临时工把数据库搞垮了(规则 No 1:总是临时工的错)。你重启数据库,开始恢复进程。
ARIES 从崩溃中恢复需要三个阶段:
- 1) 分析阶段:恢复进程读取完整的事务日志*,重建时间线,找出崩溃期间发生了什么,决定回滚哪个事务(所有没有提交命令的事务都要被回滚),哪些数据需要在崩溃时写入磁盘。
- 2) 重做阶段:这一阶段开始于分析决定的一条日志记录,使用 REDO 更新数据库,使其回到崩溃开始之前的状态。在重做期间,REDO 日志按照顺序处理(使用 LSN)。对于每一条日志,恢复进程读取包含有需要修改的数据的磁盘上的页的 LSN。如果 LSN(page_on_disk) >= LSN(log_record),意味着崩溃之前数据已经写入磁盘(但是值被日志之后、崩溃之前的操作覆盖掉了),什么都不做。如果 LSN(page_on_disk) < LSN(log_record),那么更新磁盘上的页。对于那些准备回滚的事务也需要进行重做,因为这会简化恢复进程(但是我肯定现代数据库不会这么干)。
- 3) 撤销阶段:这一阶段回滚所有在崩溃时未完成的事务。回滚开始于每一个事务的最后一个日志,按照倒序执行 UNDO 日志(使用日志记录的 PrevLSN)。
在恢复期间,事务日志必须警惕恢复管理器执行的动作,以便保证写入磁盘的数据与事务日志中的是完全同步的。一个解决方案是,删除已经撤销完成事务日志记录,但这很困难。ARIES 则是在事务日志中写入补偿日志,删除那些逻辑删除的日志记录。
当事务“手动”取消或者由锁管理器取消(终止死锁)或仅仅是由于网络失败,分析阶段是不需要的。REDO 和 UNDO 所需信息保存在两个内存中的表:
- 事务表(保存所有当前事务的状态)
- 脏页表(保存哪些数据需要被写入磁盘)
这些表由缓存管理器和事务管理器为每一个新的事务事件进行更新。由于它们是在内存中的,数据库崩溃时就会被销毁。
分析阶段的工作是在崩溃之后使用事务日志重建这两个表*。为加速分析阶段,ARIES 提供了检查点标记,其思路是,将事务表和脏页表的内容不定时写入磁盘,并且写入此时最后一个 LSN,这样在分析阶段,只有在该 LSN 之后的日志才会被分析。
总结
在写本文之前,我就知道这个话题是有多大,需要花费多少时间写一篇有深度的文章。事实证明我还是过于乐观,我花费了比预想多两倍的时间,但是我学到了很多。
如果你想很好学习数据库,我推荐阅读这篇研究论文《Architecture of a Database System》。这是一篇很好的介绍数据库的文章(110 页),适合非计算机专业人事阅读。这篇文章对编写本文计划给我很大帮助。它并没有像我的文章一样关注数据结构和算法,而是给出很多架构概念。
如果你仔细阅读本文,你应该知道数据库的强大之处。由于这是一篇很长的文章,我来提醒一下你阅读过什么:
-
- B+ 树索引的概览
- 数据库全局概览
- 基于成本的优化的概览,尤其关注于连接运算
- 缓冲池管理概览
- 事务管理概览
但是数据库要聪明得多。例如,我没有碰触下面的问题:
-
- 如何管理集群式数据库和全局事务
- 如何在数据库运行时对其创建快照
- 如何有效存储(包括压缩)数据
- 如何管理内存
所以,当你需要在充满 bug 的 NoSQL 数据库和像石头一样坚固的关系数据库之间选择时,我奉劝你要多多思考。不要将我的意思理解错了,某些 NoSQL 数据库非常棒,但是它们还年轻,只能处理某些应用的特定问题。
总结一下,如果以后有人问你,数据库是怎么工作的,我希望你不是像下面一样回答这个问题:

否则的话,你可以把这篇文章甩到他脸上。

1 个评论
great work!