
在使用 LangChain 开发第一个应用之前,我们首先要有一个能够使用的大语言模型。LangChain 支持多种模型,要选择能够在国内使用的。现在,我们使用阿里的通义千问系列。
注册百炼账号
阿里目前有百炼和灵积两个平台,二者提供的模型基本是一致的。灵积是原始的模型接口,需要通过 API/SDK 进行调用;百炼除了模型本身的 API/SDK,还提供了预置应用模板、预置业务场景模型等,同时这些功能都有可视化的操作控制台页面。我们考虑使用百炼平台。
打开百炼平台的地址,注意这里需要登录阿里云账号,如果没有,需要注册一个。新注册的账号需要在百炼平台开通大模型的使用权限。新开通的账号可以免费试用一个月,1000000 token。可以在模型广场里面查看每一个模型的费用。在模型广场最上方可以看到有个“查看我的API-KEY”,在这里可以创建 API Key。在调用之前需要创建这个 API Key。
准备 .env 文件
下面,我们尝试使用 LangChain 开发第一个 LLM 应用。
首先,需要在之前创建的 Jupyter 数据目录,新建一个 .env 文件。
可以选择直接打开这个文件夹,创建一个名为 .env 的文件。另外,也可以直接在 Jupyter 页面创建文件。由于直接新建文件不能重命名为 .env,所以使用控制台是更好的选择。
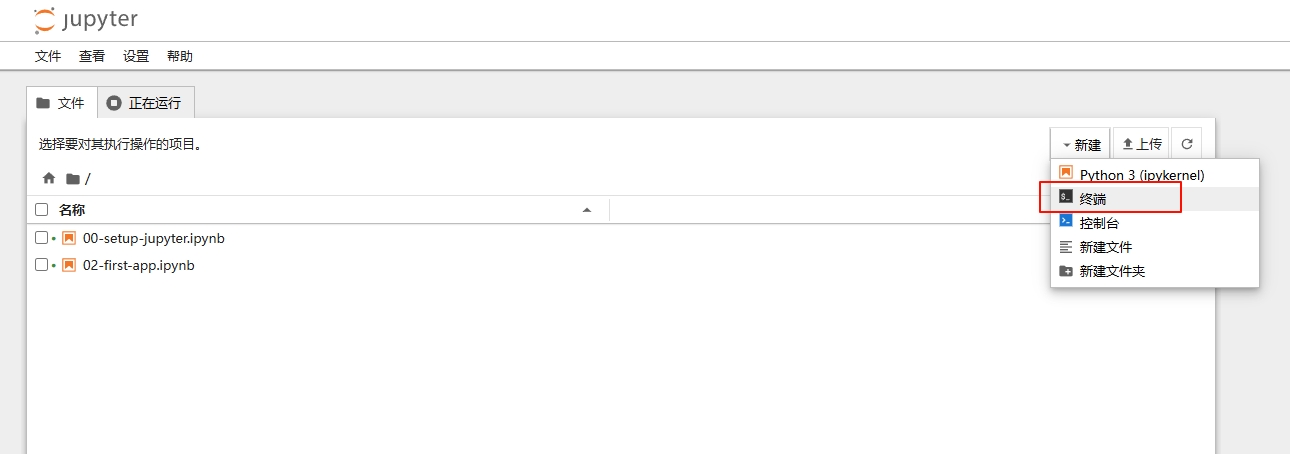
在浏览器新开标签页,输入对应终端创建文件的语句即可。比如这里使用的是 PowerShell,那么就需要
New-Item -Path "E:\Jupyter\.env" -ItemType File -Force
如果是 Bash,则使用
touch ~/jupyter/.env
注意把上面语句中的路径替换为自己的正确路径。
Jupyter 模型并不会显示隐藏文件。我们可以在文件夹直接修改 .env 文件的内容,或者开启 Jupyter 显示隐藏文件的功能。要开启 Jupyter 显示隐藏文件的功能,需要修改配置文件。配置文件的位置在上一篇中介绍过,默认在用户目录下 .jupyter 文件夹中。修改 jupyter_notebook_config.py 文件,在文件最后新增一行:
c.ContentsManager.allow_hidden = True
保存文件后,重启 Jupyter。在新打开页面的菜单中可以看到
开启“显示隐藏文件”之后,就可以在文件树中看到刚刚创建的 .env 文件。
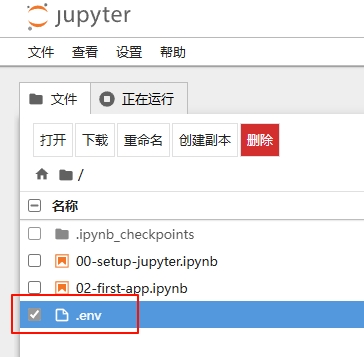
现在就可以像普通文件一样打开 .env 文件进行编辑。在 .env 文件中添加
DASHSCOPE_API_KEY=<API-KEY>
注意这里将<API-KEY>替换为刚刚申请到的实际值。
为什么需要 .env 文件?
.env 文件通常包含项目的隐私信息,包括密码、API Key 等。在项目运行时,这些信息是必须的,但这些信息不应该提交到版本控制系统中,以避免数据泄露。因此,我们将这些信息保存到单独的 .env 文件中,并且将该文件从版本控制系统忽略,以保护数据安全。
LangChain 包结构
现在,我们可以真正开始 LangChain 的开发了。
首先,我们要了解下 LangChain 包的结构。
本系列文章使用的是 LangChain v0.2,可能与其它使用 v0.1 的结构会有不同。
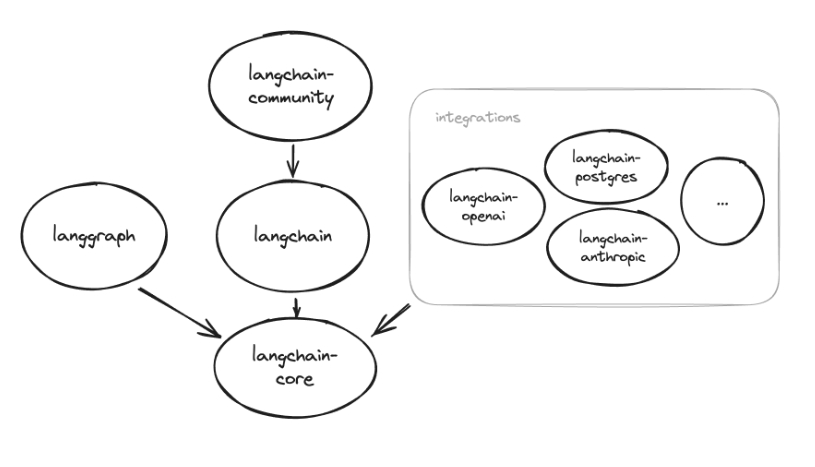
- langchain-core 是所有组件的核心。它包含其它所有组件所必须的抽象层,以及 LangChain 表达式语言。当使用
pip install langchain命令的时候,langchain-core 是被自动安装的。不过,也可以通过pip install langchain-core单独安装 langchain-core。 - langchain-community 包含与第三方的集成,比如 OpenAI,以及我们这里所需要的通义千问的接口。
- langchain-experimental 包含实验性代码,用于研究以及各种实验用途。
- langgraph 用于构建有状态的多角色应用,可以很简单地与 LangChain 结合使用,也可以独立使用。
LangChain 基本使用
了解了 LangChain 包的结构,下面我们在 Jupyter 上使用 LangChain 开始第一个应用。
%pip install langchain langchain-community dashscope python-dotenv
根据之前的介绍,我们需要安装 langchain 和 langchain-community 这两个包。dashscope 是通义千问的 SDK。另外的 python-dotenv 则用于从 .env 文件中读取信息。
安装完毕之后,通过load_dotenv()将 .env 文件的内容读取到环境变量中:
from dotenv import load_dotenv load_dotenv()
下面,我们创建通义千问模型:
from langchain_community.chat_models import ChatTongyi model = ChatTongyi(temperature=0)
现在,我们直接使用通义千问的模型。通义千问模型是ChatTongyi类。我们创建这个类的实例时,传入参数temperature=0。temperature意味着模型是否能够自由发挥,也就是结果随机程度,取值范围是[0, 1],数值越大越随机,数值越小越集中。
下面,我们就可以拿这个模型干点事了:
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="将下面的语句翻译成中文"),
HumanMessage(content="hi!"),
]
model.invoke(messages) ChatTongyi继承自ChatModel。ChatModel是 LangChain 中许多“可执行体 runnables”之一。这些可执行体具有统一的接口与其交互。为了给大模型发送消息,我们使用invoke()函数,其参数是一系列消息的列表。注意看这些参数的类型,分别是SystemMessage和HumanMessage。SystemMessage通常是发给模型的一系列消息中的第一条消息,用于规范模型的基础行为,或者是一些通用的命令。HumanMessage通常是来自于人类(也就是用户)的消息,即人机对话中“人”的角色。在这段代码中,使用SystemMessage告诉模型所需要实现的任务,即进行翻译;使用HumanMessage告诉模型,用户传递的数据,也就是需要翻译的内容。
Jupyter 会自动打印出最后一个执行的表达式的返回值。因此,这段代码在 Jupyter 会有一个输出:

可以看到,invoke()函数返回值是AIMessage类型。这个类型不仅包含模型的返回结果,而且包含了很多元数据。很多时候,我们只是想要模型的结果,也就是一个字符串类型的返回。使用输出处理器 output parser 可以达到这一目的。由于我们只是想要一个简单的字符串,可以使用StrOutputParser。
from langchain_core.output_parsers import StrOutputParser parser = StrOutputParser() result = model.invoke(messages) parser.invoke(result)
我们可以直接使用StrOutputParser,方法很明确:创建一个StrOutputParser对象,然后调用模型的invoke()函数,拿到返回结果,使用StrOutputParser处理这个返回结果。

利用StrOutputParser,我们直接拿到了模型返回的字符串,而不是AIMessage类型。
或许你会奇怪,为什么要多此一举,设计一个输出处理器呢?直接使用AIMessage.content,不就可以拿到返回结果了吗?
其实,除了直接调用,LangChain 还提供了一种“链式调用”,通过一种“链”,将模型的返回结果与处理器连接起来。这意味着,每次模型有了返回值,会像链条一样,串接调用结果处理器。使用这种链式调用很简单,就是|运算符。
chain = model | parser chain.invoke(messages)

这也正是 LangChain 名字中,“Chain” 的含义。
现在,我们把消息列表直接发送给大模型。然而,在正式使用的系统中,不会把用户提供的消息直接发给模型,而是由业务逻辑将用户提供的原始消息,转换成需要发送给模型的消息列表。这种转换一般会包括添加系统消息或者修改用户输入的格式。LangChain 使用提示词模版的概念来实现这一功能。
下面我们重新编写提示词。
from langchain_core.prompts import ChatPromptTemplate
system_template = "将下面的语句翻译成{language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
result = prompt_template.invoke({"language": "中文", "text": "hi"})
result 
这里我们提供了两个用户变量:
language:需要翻译成的语言text:需要翻译的文本
使用
("system", system_template) 构造了一个SystemMessage。HumanMessage与此类似。注意看invoke()的返回值,ChatPromptTemplate生成了前面类似的消息列表。如果我们需要直接访问这个列表,可以使用
result.to_messages()
或许你已经猜到了,为什么要添加一个ChatPromptTemplate,而不是直接使用 Python 的模板字符串。答案依然是“链”。使用|运算符,把一切都连接起来:
chain = prompt_template | model | parser
chain.invoke({"language": "中文", "text": "hi"}) 这段代码显示了,如果使用 LangChain 表达式语言 LangChain Expression Language (LCEL),把 LangChain 所有模块串接在一起。这么做有很多好处,比如优化流,以及提供追踪的能力。
