
事务管理器
最后但并不是不重要的,这一部分关于事务管理器。我们将看到如何保证每个查询都在自己的事务中进行。但是,在此之前,我们需要了解 ACID 事务的概念。
I’m on acid
一个 ACID 事务是一个工作单元,保证 4 件事:
- 原子性(Atomicity):事务“要么全做,要么全不做”,即便要持续 10 个小时。如果事务崩溃,状态将回到事务开始之前(此时事务回滚)。
- 隔离性(Isolation):同时执行两个事务 A 和 B,事务 A 和 B 的结果必须是一致的,不管 A 是在 B 之前/之后/之间完成。
- 持久性(Durability):一定事务提交(也就是成功结束),数据会保存到数据库,不管发生了什么(崩溃或者错误)。
- 一致性(Consistency):只有有效数据(按照关系约束和函数约束)可以被写入数据库。一致性与原子性和隔离性相关。

在同一个事务中,你可以运行多条 SQL 查询去读取、创建、更新和删除数据。当两个事务使用相同数据时,混乱就开始了。经典的例子是,将钱从 A 账户转移到 B 账户。假设你有两个事务:
- 事务 1 从 A 账户取出 100 美元,将它们给 B 账户
- 事务 2 从 A 账户获得 50 美元,将它们给 B 账户
如果我们回到 ACID 属性:
- 原子性保证不管在 T1 执行期间发生了什么(服务器宕机、网络异常...),你不能处于 A 账户少了 100 美元而 B 账户什么都没得到的状态(这种情况是不一致的状态)。
- 隔离性保证 T1 和 T2 同时发生,最终,A 将减少 150 美元,B 获得 150 美元,而不是,比如因为 T2 部分抵消了 T1 的某些行为,A 少了 150 美元而 B 只获得 50 美元(这种情况也是不一致的状态)。
- 持久性保证在 T1 刚刚提交之后,数据库崩溃,也不会导致 T1 的操作消失不见。
- 一致性保证系统中的钱既没有被创造也没有被销毁。
[你可以略过下面跳到下一部分,下面我所讲的对于本文其余部分不是那么重要]
很多现代数据库不会将纯粹的隔离性作为默认行为,因为这会导致很大的性能问题。SQL 标准定义了 4 种不同级别的隔离性:
- 可串行读(SQLite 的默认行为):最高级别的隔离性。同时发生的两个事务 100% 隔离。每一个事务都有它自己的“世界”。
- 可重复读(MySQL 的默认行为):每个事务都有它自己的“世界”,不过有一点例外。如果一个事务成功结束,并且添加的新的数据,这些数据对另外的正在执行的事务是可见的。但是,如果 A 修改了数据并且成功结束,这些修改对正在执行的事务是不可见的。所以,事务之间的隔离性对于新的数据而言是被打破的,对于已有数据则没有。
例如,事务 A 执行的是 “SELECT count(1) from TABLE_X”,事务 B 则向 TABLE_X 加入了新的数据并且提交,那么,事务 A 再次计算 count(1) 所获得的结果是不一致的。
这种情况被称为幻读。
- 已提交读(Oracle、PostgreSQL 和 SQL Server 的默认行为):这是可重复读 + 一个新的隔离性打破。如果事务 A 读取数据 D,然后该数据被事务 B 修改(或删除)并且提交,A 再次读取 D 将会看到由 B 所做的修改(或删除)
这被称为不可重复读。
- 未提交读:最低级别的隔离。这是已提交读 + 一个新的隔离性打破。如果事务 A 读取数据 D,然后数据 D 被事务 B 修改(并未提交,继续运行),如果 A 再次读取 D,那么它将看到被修改的数据。如果事务 B 回滚,那么事务 A 第二次读出的数据 D 是没有意义的,因为事务 B 所做的修改已经被撤消了(事务 B 已经回滚)。
这被称为脏读。
大多数数据库添加了自定义的隔离级别(例如 PostgreSQL、Oracle 和 SQL Server 的快照隔离)。另外,大多数数据库并没有实现 SQL 标准的全部级别(尤其是未提交读级别)。
隔离性的默认级别可以由用户/开发者在开始连接时指定(只需要添加很简单的一行代码)。
并发控制
保证隔离性、一致性和原子性的真正问题是在同一数据上的写操作(增加、修改和删除):
- 如果所有事务都是读数据,它们可以同时进行,不需要修改另外事务的行为
- 如果这些事务中(至少)一个是修改数据,其余事务读取数据,那么,数据库需要找到一种方式向其它事务隐藏修改。并且,数据库还需要确保这种修改不会被不能看到修改的其它事务覆盖掉。
这个问题称为并发控制。
解决这个问题的最简单方法是,一个一个执行事务(串行)。但是这没有一点可扩展性,并且在多核处理器的服务器上只能有一个核在工作,非常浪费资源...
解决这一问题的理想方法是,每次一个事务被创建或取消时:
- 监控所有事务的所有操作
- 检查两个(或多个)事务的某些部分是不是因为读/写相同数据导致冲突
- 在发生了冲突的数据内部进行操作的重排序,减小发生冲突的部分
- 以特定顺序执行冲突部分(与此同时,不冲突的事务继续并发执行)
- 考虑是不是有事务可以被取消
更正式的说,这是一个带有冲突计划的调度问题。进一步说,这是一个非常困难、消耗大量 CPU 资源的优化问题。企业数据库不可能等待几个小时去为每一个新的事务事件找到最好的调度。因此,数据库使用不那么理想的实现,通过浪费一些时间来解决冲突的事务。
锁管理器
为了解决这一问题,大多数数据库使用锁(lock)和/或数据版本管理(data versioning)。这是一个很大的话题,我主要关注于锁的部分,之后将简单介绍数据版本。
悲观锁
锁背后的思路是:
- 如果事务需要数据
- 锁住数据
- 如果另外的事务也需要这个数据
- 让它等待,直到第一个事务释放了数据
这种锁被称为互斥锁。
但是,对于那些只需要读数据的事务而言,互斥锁非常昂贵,因为它强制只需要读取相同数据的事务等待。这就是为什么有另外一种类型的锁:共享锁。
使用共享锁:
- 如果事务需要读取数据 A
- 它使用共享锁锁住数据,读取数据
- 第二个事务只需要读取数据 A
- 它用共享锁锁住数据,读取数据
- 第三个事务想要改变数据 A
- 它想要用互斥锁锁住数据,但是它必须等待另外两个事务释放其共享锁,才能够用自己的互斥锁锁住数据 A
但是,如果数据有互斥锁,即便事务只需要读取数据,它还是得等待互斥锁释放掉,才能够用共享锁锁住数据。
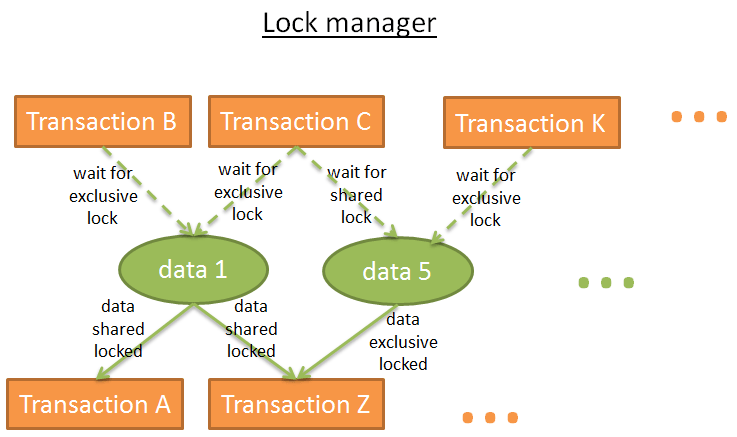
锁管理器就是加锁和解锁的进程。它将锁存储在哈希表(其键值就是需要加锁的数据)中,知道每一个数据的信息:
- 哪些事务正在锁住数据
- 哪些事务正在等待数据
死锁
但是,锁的使用可能会导致这样一种情况:两个事务永远等待数据的锁:

在这个图中:
- 事务 A 为 data1 加了互斥锁,等待获得 data2
- 事务 B 为 data2 加了互斥锁,等待获得 data1
这种情况被称为死锁。
在死锁中,锁管理器决定哪一个事务被取消(回滚),以便移除死锁。这种决定并不那么简单:
- 取消修改了最少数据的那个事务更好一些吗(这样就回滚的代价是最小的)?
- 取消执行时间最短的那个事务更好一些吗(因为其它事务都执行了更长的时间)?
- 取消最快执行完毕的那个事务更好一些吗(避免出现饥饿)?
- 对于那个回滚,究竟有多少事务会收回滚的影响?
在做出选择之前,数据库需要首先检查是不是真的存在死锁。
哈希表可以看做一个图(与上面的图类似)。如果图中存在环,说明存在死锁。因为检查环是很昂贵的(包含所有锁的图是非常大的),所以通常会使用一种简单的实现:使用超时。如果锁没有在规定时间内获得,事务就进入了死锁状态。
锁管理器在加锁之前也可以检查这个锁会不会导致死锁。但是一个完美的实现同样代价昂贵。因此,所做的先期检查只是基于一些基本的规则。
两阶段加锁
保证纯粹隔离性的最简单方法是,在事务开始时获得锁,在事务结束时释放锁。这意味着事务必须在开始之前等待它的所有的锁,在其结束时等待其持有的锁都释放掉。这当然可以工作,但是等待所有的锁会产生大量时间浪费。
更多的方法是两阶段加锁协议(DB2 和 SQL Server 使用)。在这个协议中,事务分为两个阶段:
- 生长阶段(growing phase),事务可以获得锁,但是不能释放锁
- 收缩阶段(shrinking phase),事务可以释放锁(对于那些已经处理过、不再需要的数据),但是不能获得新锁
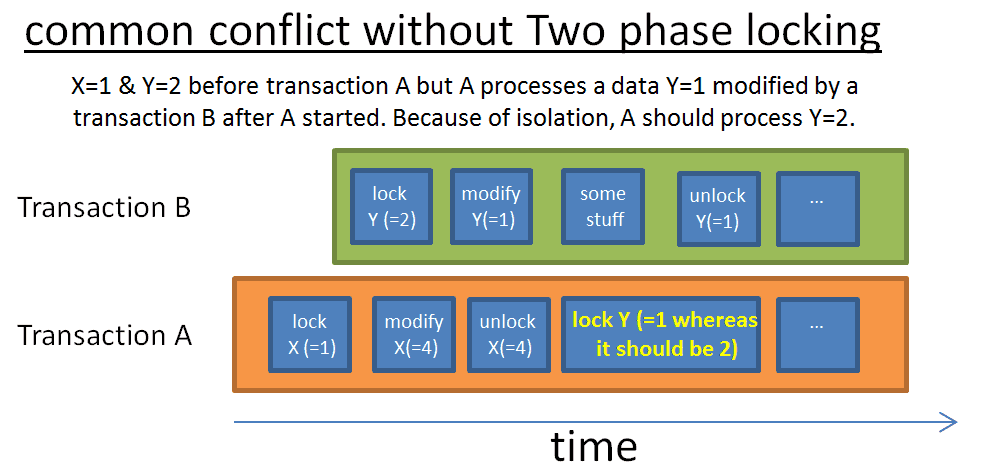
这两个简单规则背后的思路是:
- 释放掉不再使用的锁,减少其它事务等待这些锁的等待时间
- 避免事务开始之后获取到被修改的数据的情况,这种情况不能保证事务请求的第一个数据的一致性
这个协议工作得很好,除了一个修改了数据又释放掉相关锁的事务取消(回滚)。在这种情况下,另外的事务读到的是被修改的数据值,而这个值马上就要被回滚。为避免这一问题,所有的互斥锁必须在事务最后释放。
额外的话
当然,实际的数据库使用了更复杂的系统,引入了更多的锁类型(例如意向锁)和更细致的粒度(在行、页、分区、表和表空间加锁),但是思路是一致的。
我只表述了纯粹的基于锁的实现。数据版本管理是解决这一问题的另外的方法。
数据版本管理背后的思想是:
- 每一个事务可以在相同时间修改相同数据
- 每一个事务都保存这个数据的自己的备份(或称版本)
- 如果两个事务修改相同数据,只有一个修改会被接受,另外一个则会被拒绝,其相关事务会被回滚(可能会重新运行)。
基于以下原因,数据版本管理可以提高性能:
- 读事务不需要锁住写事务
- 写事务不需要阻塞读事务
- 没有来自“又大又慢的”锁管理器的开销
一切都比锁要好,除了两个事务写同样的数据。另外,你可以很快达到巨大的磁盘空间消耗。
数据版本控制和锁是两种不同视角:乐观锁和悲观锁。二者都有优缺点,取决于使用用例(读更多还是写更多)。对于数据版本的详细信息,我推荐阅读有关 PostgreSQL 如何实现多版本并发控制的这篇非常好的论文。
某些数据库,例如 DB2(DB2 9.7 之前)和 SQL Server (不包括快照隔离)只支持锁。另外的数据库,比如 PostgreSQL、MySQL 和 Oracle 混合使用锁和数据版本。我还没有发现只使用数据版本的数据库(如果你发现了纯粹基于数据版本的数据库,请告诉我)。
[2015 年 8 月 20 日更新] 有位读者告诉我:
Firebird 和 Interbase 使用了版本,没有使用记录锁。
对于索引,版本有一种非常有趣的影响:有时唯一索引可能包含重复数据;索引中的记录数可能比表行数更多等。
如果你阅读了有关隔离性的不同级别,当提高隔离级别时,也就增加了锁的数量,因此,事务将要花费更多时间等待锁。这也就是为什么数据库不默认使用最高级别的隔离(可串行读)。
与往常一样,你可以自行查阅主流数据库的相关文档(例如 MySQL、PostgreSQL 和 Oracle)。
