
数据管理器

在这一步,查询管理器已经执行了查询,需要从表和索引获取数据。查询管理器请求数据管理器读取数据,但是这里有两个问题:
- 关系数据库使用的是事务模型。所以,当其他人正在使用或修改数据时,你不能同时获取数据。
- 数据获取是数据库中最慢的操作,因此,数据管理器需要足够聪明,以便将数据缓存在内存缓冲区中。
在这部分,我们将了解关系数据库是如何处理这两个问题的。我不会详细介绍数据管理器是如何得到数据的,这并不是最重要的(并且这篇文章也不足够那么长)。
缓存管理器
正如我说的那样,数据库的主要瓶颈是磁盘 I/O。为了改进性能,现代数据库都使用了缓存管理器。

查询执行器并不会直接从文件系统取得数据,而是向缓存管理器请求数据。缓存管理器有一个内存中缓存,称为缓冲池。从内存获取数据能够显著提升数据库性能。但是,明确给出一个量级也是非常困难的,因为这取决于你需要的操作:
- 顺序访问(例如,全表扫描)或随机访问(例如,通过 row id 访问)
- 读或写
以及数据库使用的磁盘类型:
- 7.2k/10k/15k RPM HDD
- SSD
- RAID 1/5/…
但是,我可以说,内存要比磁盘快 100 到 10万倍。
但是,这导致了另外的问题(一直伴随着数据库)。缓存管理器需要在查询执行器使用数据之前就将数据放在内存,否则,查询管理器不得不等待从缓慢的磁盘读取数据。
预读取
这个问题称为预读取。查询执行器知道它需要的数据,因为它知道查询的整个流程以及通过统计获得的有关磁盘上数据的结构知识。下面就是思路:
- 当查询执行器正在处理它的第一批数据时
- 它请求缓存管理器将第二批数据预先加载到内存
- 当它开始处理第二批数据时
- 它请求缓存管理器将第三批数据预先加载到内存,并且告诉缓存管理器,第一批数据可以从缓存清除了
- …
缓存管理器将所有数据都存入其缓冲池。为了知道数据是否还需要,缓存管理器为那些已缓存的数据添加了额外的信息(称为栓,latch)。
有时,查询执行器并不知道它需要什么数据,某些数据库并不提供这种功能。相反,它们使用一种推断式预读取(例如,如果查询执行器请求数据 1,3,5,那么,它很有可能请求数据7,9,11)或者串行预读取(在这种情况下,缓存管理器从磁盘加载当前数据之后下一批连续数据)。
为了监控预读取是不是工作良好,现代数据库提供了称为缓冲/缓存命中率(buffer/cache hit ratio)的度量。这个命中率显示了请求的数据在缓冲区被找到,而不是请求磁盘访问的频率。
注意,不好的缓冲命中率并不意味着缓存不能好好工作。更多信息,可以阅读 Oracle 文档。
但是,缓冲受到内存总数的限制。因此,为了加载新的数据,缓冲需要移除旧的数据。加载和移除缓存数据需要消耗一定的磁盘和网络 I/O。如果你的查询需要频繁执行,将该查询使用的数据加载然后移除就不是那么高效了。为解决这一问题,现代数据库使用了一种缓冲替代策略。
缓冲替换策略
大多数现代数据库(包括 SQL Server、MySQL、Oracle 和 DB2)都使用了 LRU 算法。
LRU
LRU 意思是 Least Recently Used(最近最少使用)。算法思想是,将最近使用的数据放在缓冲区,最近使用的数据更有可能再次使用。
下面是一个例子:
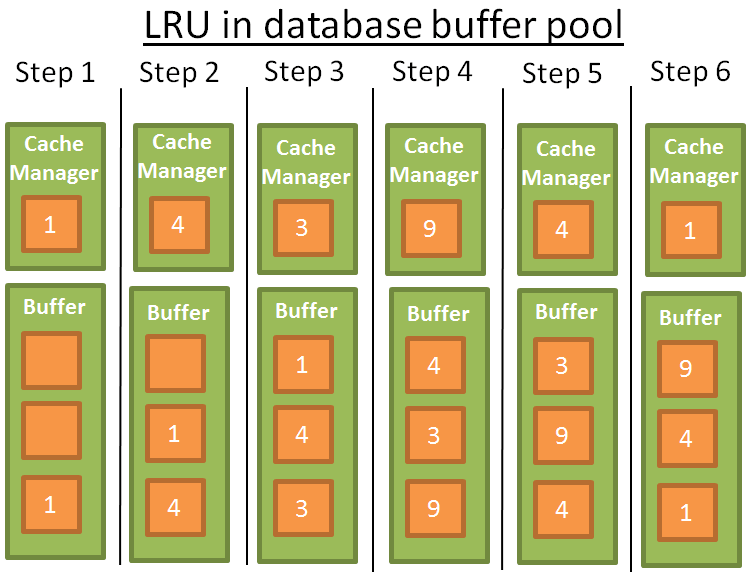
为了便于理解,假设缓冲区的数据没有被栓锁住(因此是可以被移除的)。在这个例子中,缓冲区可以储存 3 个元素:
- 1: 缓存管理器使用数据 1,将数据放入空的缓冲区
- 2: 缓存管理器使用数据 4,将数据放入有了加载的缓冲区
- 3: 缓存管理器使用数据 3,将数据放入有了加载的缓冲区
- 4: 缓存管理器使用数据 9。缓冲区已经满了,因为数据 1 是最早使用的数据,因此数据 1 被移除。数据 9 添加入缓冲区
- 5: 缓存管理器使用数据 4。数据 4 已经在缓冲区了,因此它又变成了最近被使用的数据
- 6: 缓存管理器使用数据 1。缓冲区已经满了,因为数据 9 是最早使用的数据,因此数据 9 被移除。数据 1 添加入缓冲器
- …
这个算法工作得很好,但是有一些限制。如果是一个大表的全表扫描该怎么办?换句话说,表或索引的大小超过了缓冲区的大小,会发生什么?使用这个算法,尽管全表扫描获取的那些数据只使用一次,但是却导致缓存中保存的所有数据都会被清除。
改进
为避免这种问题,某些数据库添加了额外的规则。例如,根据 Oracle 文档:
“对于非常大的表,数据库通常使用一次重定向路径读取,直接加载块 […],避免从缓冲区获取数据。对于中等大小的表,数据库可能使用直接读取,也可能使用缓存读取。如果数据库决定使用缓存读取,那么,数据库会替换 LRU 列表末尾的块,避免通过扫描缓冲区而进行的有效清除。”
另外可能的解决是使用改进版本的 LRU,称为 LRU-K。例如,SQL Server 使用的是 LRU-K,其中 K =2。
这种算法的思路是,考虑更多历史。简单的 LRU(也被称为 LRU-K,其中 K =1),算法只考虑数据最后一次被使用的情况。按照 LRU-K:
- 它需要考虑最后 K 次数据被使用
- 按照数据被使用的次数增加一个权重
- 如果一批新的数据加载到内存,旧的但是经常被使用的数据不会被移除(因为它们权重更高)
- 但是算法不会将不再使用的数据保存在缓存
- 所以,如果数据不再被使用,随着时间的流逝,其权重也会降低
权重计算的成本非常高,这也就是为什么 SQL Server 只使用 K=2。这个值只一个可接受的开销。
更深入了解 LRU-K,可以阅读原始研究论文(1993):The LRU-K page replacement algorithm for database disk buffering。
其它算法
当然,管理缓存还有其它的算法,比如:
- 2Q(一种类似于 LRU-K 的算法)
- CLOCK(一种类似于 LRU-K 的算法)
- MRU(最近最多使用,使用类似 LRU 的逻辑,但是另外的规则)
- LRFU(最少最近频繁使用)
- …
有些数据库允许使用除默认算法外的另外的算法。
写缓存
我只讨论了读缓存,也就是在使用之前加载数据。但是,数据库还有写缓存,即保存数据然后将数据一次性写入磁盘,而不是每次写入数据,造成大量单次磁盘访问。
记住,缓冲存储页(page,最小的数据单位),不是行(行是逻辑/人可读的数据)。当缓冲池中的页被修改但是没有写入磁盘时,这个页就是脏(dirty)的。有很多算法确定什么是将脏页写入磁盘的最好时刻,但是这部分内容高度依赖于事务的术语,我们将在下一章节详细介绍。
