
概览
前面我们已经介绍过数据库内部的基本组件。现在,我们需要回到最高层。
数据库是一种能够轻松访问和修改的信息集合。但是,简单的文件也可以做相同的事情。事实上,最简单的数据库,比如 SQLite,就是一系列文件。但是,SQLite 是一组被精心组织的文件,允许你:
- 利用事务保证数据安全和一致
- 即使你处理百万级别的数据,它的处理速度依然很快
一般地,数据库可以看作下图:
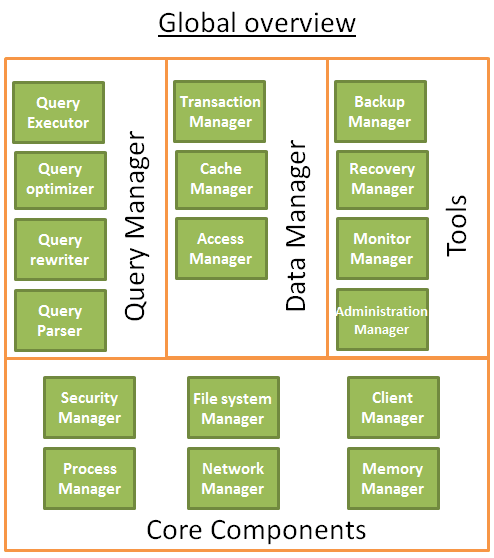
在开始写这部分之前,我阅读了很多描述数据库的书和论文,甚至是数据库的源代码。所以,不要太纠结我是怎么组织数据库的,或者我是怎么给它命名的,因为我必须为了本书的主题做出一定的取舍。真正重要的是这些不同的组件。总的思想是,数据库可以分为多个相互联系的多种组件。
核心组件
- 进程管理器:很多数据库都需要管理进程池或线程池。而且,为了改进那么几纳秒,一些现代数据库还会使用它们自己的线程,而不是操作系统提供的线程。
- 网络管理器:网络 I/O 是个大问题,尤其对于分布式数据库。这也就是为什么有些数据库会有它们自己的网络管理器。
- 文件系统管理器:磁盘 I/O 是数据库的最大瓶颈。因此,有一个能够完美地处理操作系统文件系统,甚至取代操作系统文件系统的文件系统管理器就变得非常重要。
- 内存管理器:为了避免大量磁盘 I/O,大容量内存必不可少。但是,如果你有很大数量的内存,你就需要一个高效的内存管理器。尤其是当你在同一时间有多个查询时。
- 安全管理器:管理用户的认证和授权。
- 客户端管理器:管理客户端连接。
- …
工具
- 备份管理器:保存和恢复数据库。
- 恢复管理器:在数据库崩溃之后将其重启到一个一致性状态。
- 监控管理器:记录数据库动作日志,提供工具监控数据库。
- 管理管理器:保存元数据(比如表的名字和结构等),提供工具管理数据库、模式和表空间等。
- …
查询管理器
- 查询处理器:检查查询语句属否合法。
- 查询重写器:为查询语句预优化。
- 查询优化器:优化查询语句。
- 查询执行器:编译并执行查询语句。
数据管理器
- 事务管理器:处理事务。
- 缓存管理器:在使用数据之前或将数据写入磁盘之前,将数据放到内存中。
- 数据访问管理器:访问磁盘上的数据。
本文剩下的部分,我将会详细阐述数据库是如何通过如下步骤管理一条 SQL 查询:
- 客户端管理器
- 查询管理其
- 数据管理器(这部分也会包括恢复管理器)
客户端管理器
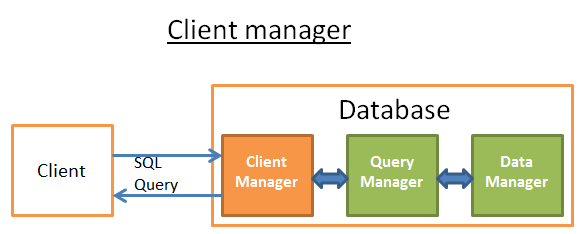
客户端管理器处理数据库与客户端之间的通讯。所谓客户端,可以是(网络)服务器或最终用户/应用程序。客户端管理器提供了多种不同方法访问数据库,包括一系列著名的 API:JDBC、ODBC、OLE-DB 等。
客户端管理器还提供了数据库访问的专有 API。
当你连接到一个数据库时:
- 管理器首先检查你的认证(用户名和密码),然后检查你是不是有使用数据库的授权。访问权限由 DBA 设置。
- 然后,管理器检查是不是有一个可用的进程(或线程)可以管理你的查询。
- 管理器还要检查数据库是不是处于过载状态。
- 管理器会等待一段时间,以便获取必要的资源。如果等待超时,它就会管理连接,然后返回一个人可读的错误信息。
- 然后,管理器会将你的查询发送到查询管理器,这样,你的查询就被处理了。
- 由于查询处理并不是“要么全部,要么没有”,只要它从查询管理器取得数据,它就会将这部分数据保存在一个缓冲区,然后开始将数据发送给你。
- 如果出现了问题,它就会停止连接,返回给你可读的原因,然后释放资源。
查询管理器
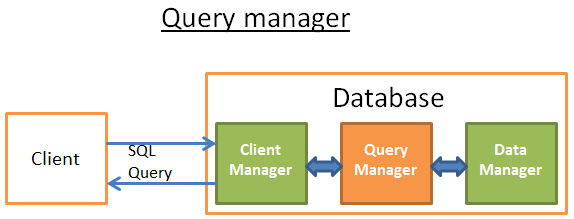
这部分是数据库的强大之处。在这部分,一个写得有问题的查询语句会被转换成一个能够快速执行的代码。然后,代码被执行,结果返回给客户端管理器。这是多步操作:
- 首先,查询语句会被解析(parse),检查是不是合法。
- 然后,查询语句会被重写(rewrite),移除没用的操作,增加一些预先的优化。
- 然后,查询语句会被优化(optimize),改进性能,转换成一个执行和数据访问计划。
- 然后,这个计划会被编译(compile),
- 最后,这个计划会被执行(execute)。
在这部分,我不会对最后两点作过多的介绍,因为它们并不是那么重要。
在阅读完本部分时,如果你还想进一步学习,我推荐阅读下面的文章:
- 有关基于成本的优化的原始研究论文(1979):Access Path Selection in a Relational Database Management System。这篇论文只有 12 页,只要有计算机科学知识的一般水平就足以理解。
- 一篇关于 DB2 9.X 如何优化查询的非常好并且很有深度的报告:这里。
- 一篇关于 PostgreSQL 如何优化查询的非常好的报告:这里。这篇文章是最容易理解的,因为它主要是关于“给我看看在这些情形下,PostgreSQL 给出的查询计划是怎样的”以及“让我们看看 PostgreSQL 使用的算法”。
- 有关优化的 SQLite 官方文档。因为 SQLite 使用的规则都很简单,所以这篇文章比较“好懂”。并且,这是真正解释如何工作的唯一官方文档。
- 一篇关于 SQL Server 2005 如何优化查询的非常好的报告:这里。
- 有关 Oracle 12c 优化的白皮书:这里。
- 来自《DATABASE SYSTEM CONCEPTS》作者的关于查询优化的 2 个理论课程:这里以及这里。着眼于磁盘 I/O 消耗,但是要求一定的计算机科学知识。
- 另外一个理论课程更好理解,但是仅着重于连接操作和磁盘 I/O。
查询解析器
每一个 SQL 语句都会发送给解析器,后者将检查语句的语法。如果查询语句中有错误,解析器会拒绝该查询。例如,如果你写的是“SLECT ...” 而不是“SELECT ...”,那么处理就到此为止了。
但是,我们会深入探讨这一点。解析器还会检查关键字使用是不是顺序正确。例如,WHERE 出现在 SELECT 之前是不允许的。
然后,查询中的表格和字段都会被分析。解析器使用数据库元数据检查:
- 表格是否存在
- 表格的字段是否存在
- 该字段是否允许执行该操作(例如,不允许将整型同字符串进行比较,不允许使用整型调用 substring() 函数)
然后,解析器检查你是不是有权限在查询中读取(或写入)数据表。再说一遍,这些表格的访问权限是由你的 DBA 设置的。
在解析期间,SQL 查询会被转换成一种内部的表示形式(通常是一棵树)。
如果所有一切正常,那么这个内部表示形式就会被发送给查询重写器。
查询重写器
在这一步,我们有一个查询的内部表示。重写器的目的是:
- 预优化查询
- 避免不必要的操作
- 帮助优化器找到最好的可行方案
重写器会在查询语句上执行一系列已知的规则。如果查询符合某一规则的模式,那么该规则就会被应用到这个查询,查询会被重写。下面是一组简单的(可选)规则列表:
- 视图合并:如果查询中使用了视图,那么视图会被转换成该视图的 SQL 语句。
- 子查询扁平化:子查询会明显增加优化的难度,因此,重写器会尝试修改带有子查询的查询,以便去除子查询。
例如,
SELECT PERSON.*
FROM PERSON
WHERE PERSON.person_key IN
(SELECT MAILS.person_key
FROM MAILS
WHERE MAILS.mail LIKE 'christophe%'); 可以替换为
SELECT PERSON.*
FROM PERSON, MAILS
WHERE PERSON.person_key = MAILS.person_key
and MAILS.mail LIKE 'christophe%';
- 移除不必要的操作:例如,如果你在有 UNIQUE 约束来避免数据出现重复的地方使用了 DISTINCT,那么,DISTINCT 关键字就会被移除。
- 移除冗余连接:如果你有两个相同的连接,可能是因为在视图中已经暗含了一个连接条件,或者是由于传递律出现了一个没有用的连接,该连接就会被移除。
- 常量算术计算:如果你的语句需要计算,那么,计算结果就在重写中就获得。例如,WHERE AGE > 10+2 会传换成 WHERE AGE > 12;TODATE("日期") 则会直接转换成所需的日期格式。
- (高级)分区裁剪:如果你使用的是分区表,重写器会找出使用了哪些分区。
- (高级)物化视图重写:如果物化视图符合查询语句中谓词的子集,重写器会检查视图是不是最新的,并且修改查询优先使用物化视图而不是原始表。
- (高级)自定义规则:如果有自定义规则修改查询(比如 Oracle 策略),重写器会执行这些规则。
- (高级)OLAP 变形:应用分析/窗口函数,star join,rollup 函数等(但是我不确定这部分是由重写器还是优化器完成的,由于这部分处理非常相近,所以很可能是依赖于数据库的实现)。
重写后的查询会发送给查询优化器,这时候,有趣的才真正开始!
统计
在我们学习数据库如何优化查询之前,我们需要先讨论下统计。因为没有统计的话,数据库是很愚蠢的。如果你不告诉数据库去分析下它们自己的数据,它们是不会主动去做的,会得到一个很糟糕的假设。
但是,数据库需要什么类型的信息?
我需要(简短地)讨论下数据库和操作系统是如何存储数据的。数据存储的最小单位是页(page)或者块(block),默认是 4 或 8 KB。这意味着如果你只需要 1 KB,它依然会占用整个页。如果一个页是 8 KB,那么你就会浪费 7 KB。
回到统计!当你要求数据库收集统计信息时,它会计算:
- 表格中的行数或页数
- 表格中每一列:
- 不同的数据值
- 数据值的长度(最大值、最小值、平均值)
- 数据范围的信息(最大值、最小值、平均值)
- 表格索引的信息
这些统计可以帮助优化器估算查询中的磁盘 I/O、CPU 和内存使用。
每一列的统计都很重要。例如,如果 PERSON 表需要连接 2 列:LAST_NAME 和 FIRST_NAME。通过统计,数据库就会知道 FIRST_NAME 列只有 1000 个不同的值,而 LAST_NAME 则有 1000000 个不同值。因此,数据库会使用 LAST_NAME, FIRST_NAME 连接数据,而不是 FIRST_NAME,LAST_NAME,这会产生更少的比较步骤,因为 LAST_NAME 一般不会相同,有可能只需要比较 2(或 3)个字符就可以了。
但是这些只是基本统计。你可以要求数据库计算高级统计,称为直方图(histograms)。直方图代表列内部值的分布。例如:
- 最常见的值
- 分位数
- …
这些额外统计将帮助数据库找到更好的查询计划。这种统计对于相等谓词(例如,WHERE AGE = 18)或范围谓词(例如,WHERE AGE > 10 AND AGE < 40)尤其有效,因为数据库可以获得有关这两种谓词数据行分布的更好信息(注意,这种概念的专业术语是选择性 selectivity)。
统计信息存储在数据库的元数据中。例如,你可以在下面位置看到(非分割)表的统计信息:
- Oracle 数据库在 USER/ALL/DBA_TABLES 和 USER/ALL/DBA_TAB_COLUMNS
- DB2 数据库在 SYSCAT.TABLES 和 SYSCAT.COLUMNS
统计信息必须及时更新。最糟糕的是,当数据库表实际有 1000000 行时,它却认为只有 500 行。统计的缺点是,需要花费大量时间进行计算。这也就是为什么大多数数据库并不会自动计算统计信息。当数据库有百万级别的数据量时,计算统计信息会非常困难。在这种情况下,你可以选择只计算基本统计或计算数据样本库的统计。
例如,我曾经在一个项目工作,该项目中每一个表的数据量达到亿级别。我选择其中 10% 计算统计数据,这节省了大量时间。但是,最终结果表明这是一个错误的决定,因为 Oracle 10G 选择的这 10% 恰恰是一个特殊表的特殊字段,根本不能代表其余 100% 的数据(对于 1 亿的数据量,这并不经常发生)。这个错误的统计使得一个本应只有 30 秒的查询消耗了近 8 小时。查找问题的过程简直就是噩梦。这个故事说明了统计是有多么重要。
注意,每种数据库都会有特殊的高级统计。如果你想要了解更多,可以阅读数据库文档。就像前面说的,当我试图了解统计是如何使用的时候,发现的最好的官方文档就是来自 PostgreSQL 的一篇。
