
简单的例子
我们已经见识到了 3 种类型的连接操作。
现在,假设我们需要连接 5 张表来获取一个人的全部信息。一个人有:
- 多个手机(MOBILES)
- 多个邮箱(MAILS)
- 多个地址(ADRESSES)
- 多个银行账户(BANK_ACCOUNTS)
换句话说,我们需要能够快速地找出下面查询的结果:
SELECT * from PERSON, MOBILES, MAILS,ADRESSES, BANK_ACCOUNTS
WHERE
PERSON.PERSON_ID = MOBILES.PERSON_ID
AND PERSON.PERSON_ID = MAILS.PERSON_ID
AND PERSON.PERSON_ID = ADRESSES.PERSON_ID
AND PERSON.PERSON_ID = BANK_ACCOUNTS.PERSON_ID 作为一个查询优化器,我必须找到最好的途径来处理数据。但是,这里有两个问题:
- 针对每一个连接,我需要选择使用哪种类型?
我有 3 种类型可供选择(哈希连接、归并连接和嵌套连接),每种类型可以使用 0 个、1 个或者 2 个索引(并不是说有不同类型的索引)。
- 我应该按照怎样的顺序计算连接?
例如,下面的图显示了 4 张表的 3 个连接的不同计划: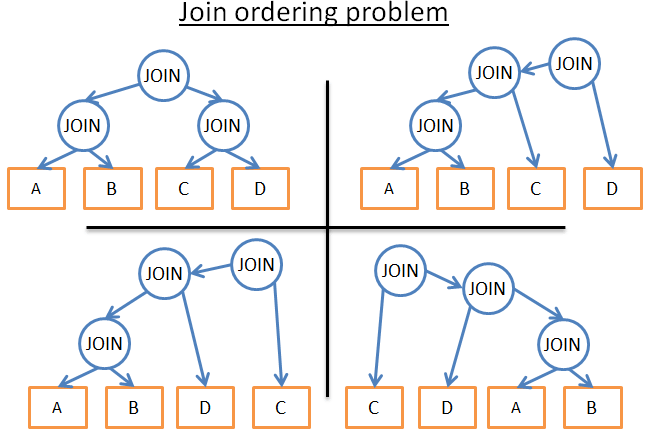
现在我有下面几个选择:
- 1) 暴力实现
利用数据库统计,我计算得出每种计划的成本,选择最好的一个。但是这有很多可能性。对于一个给定的连接顺序,每种连接有 3 种可能:哈希连接、归并连接和嵌套连接。那么,对于给定的连接顺序,一共有 34 种可能性。连接顺序是二叉树上面的排序问题,有 (2*4)!/(4+1)! 种排序。对于这个简单的问题,我们有 34*(2*4)!/(4+1)! 种可能性。
用“人话”来说,一共有 27 216 种可能的计划。现在,如果我增加归并连接可以使用的 B+ 树索引数为 0、1 或 2,可能的计划数变成了 210 000。我记得我说过这个查询是非常简单的吗?
- 2) 哭着说不干了
这的确非常解气,但是你没法拿到你要的结果,我也需要花钱去缴我的账单。
- 3) 我只试几个计划,从中选择一个成本最低的
因为我不是超人,我没办法计算每一个计划的成本。所以,我随机地选择所有可能的计划的一个子集,计算其成本,给你这个子集中最好的计划。
- 4) 我应用一个非常聪明的能够减少可能的计划数的规则
有两种类型的规则:
“逻辑”规则,用于移除没什么用的可能计划,但是并不能过滤掉大部分可能的计划。例如:“嵌套循环连接的内关系必须是最小的数据集”。
我接受不去找到最好的解决方案,而是应用积极的规则来减少可能性的数量。例如,“如果关系很少,使用嵌套循环连接,不使用归并连接和哈希连接”。
在这个简单的例子中,最终我的结果还会有很多种可能性。但是,在真实的查询中,还有其它的关系运算符,例如 OUTER JOIN、CROSS JOIN、GROUP BY、ORDER BY、PROJECTION、UNION、INTERSECT、DISTINCT … 这意味着甚至有更多可能性。
那么,数据库是怎么做的?
动态规划、贪心算法和启发式算法
关系数据库会尝试我前面说的各种实现。优化器的真正工作是在有限时间内找出一个好的解决方案。
大多数时间,优化器并不是找到最好的解决方案,而是一个“好的”解决方案。
对于小的查询,暴力实现是可能的。但是,还有一种方法可以避免不必要的计算,从而使得一些中级查询也可以使用暴力实现。这种方法叫做动态规划。
动态规划
这个词背后的思想是,大部分执行计划都是相似的。如果你看一下下面的计划:
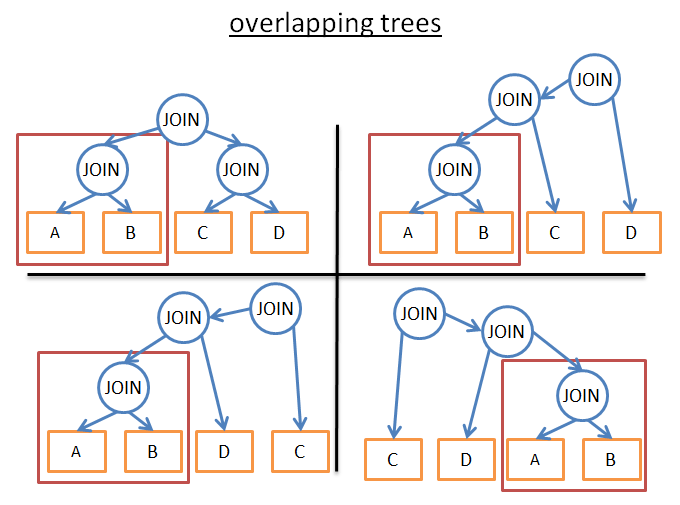
这些计划都共享了相同的 (A JOIN B) 子树。因此,不需要在每一个计划都计算这个子树的成本,我们只需要计算一次,将计算所得的成本保存下来,当再次见到这个子树时,复用这个计算结果即可。正式的说法是,我们面对的是一个重叠问题。为避免中间结果的额外计算,我们使用了记忆技术。
利用这一技术,我们的时间复杂度不是 (2*N)!/(N+1)!,“仅仅”是3N。在我们前面四个连接的例子中,这意味着可能性将从 336 降低到 81。如果你的查询更大(比如 8 个连接的查询,这其实也算不上大),这意味着可能性从57 657 600 降低到 6561。
对于计算机专业人士,我在前面提到过的正式课程中找到一个算法。我不会解释这个算法,所以,如果你懂动态规划或者对算法有兴趣的话,可以仔细阅读下面的算法(我已经警告过你了!):
procedure findbestplan(S)
if (bestplan[S].cost infinite)
return bestplan[S]
// else bestplan[S] has not been computed earlier, compute it now
if (S contains only 1 relation)
set bestplan[S].plan and bestplan[S].cost based on the best way
of accessing S /* Using selections on S and indices on S */
else for each non-empty subset S1 of S such that S1 != S
P1= findbestplan(S1)
P2= findbestplan(S - S1)
A = best algorithm for joining results of P1 and P2
cost = P1.cost + P2.cost + cost of A
if cost < bestplan[S].cost
bestplan[S].cost = cost
bestplan[S].plan = “execute P1.plan; execute P2.plan;
join results of P1 and P2 using A”
return bestplan[S]
对于更大的查询,你还是可以继续使用动态规划算法,但是还可以有另外的规则(启发式算法)来移除一些可能性:
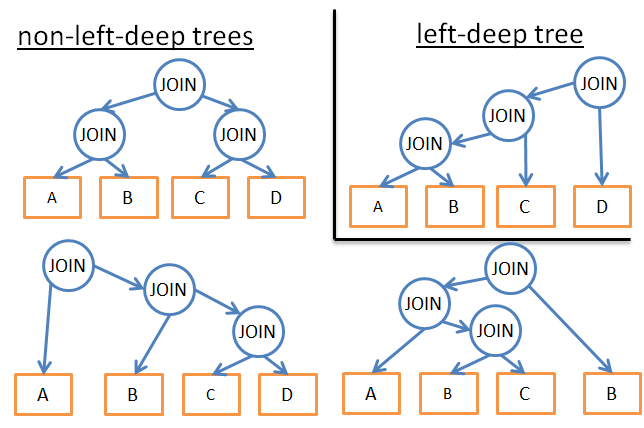
- 如果我们分析唯一类型的计划(例如左深树),我们可以做到 n*2n 而不是 3n

- 如果我们添加逻辑规则来避免某些模式的计划(例如,“如果一张表对于给定谓词包含一个索引,那么就要在索引而不是表上应用归并连接”),那么就可以减少可能性的数量而不会影响到最好可能的解决方案。
- 如果我们在工作流添加规则(例如,“在其它关系操作之前应用连接”),同样会减少很多可能性。
- …
贪心算法
为了处理非常大的查询,或者为了快速获得答案(针对不是那么快的查询),需要使用另外一种类型的算法——贪心算法。
贪心算法的思路是,利用某种规则(或启发式)构建一种渐进的查询计划。根据这种规则,贪心算法每次找到一个问题的最佳解的一个步骤。算法从一个 JOIN 开始查询计划。然后,在之后的每一步种,算法按照相同规则,向查询计划增加一个新的 JOIN。
下面我们看一个简单的例子。假设我们有一个查询,包含五张表(A,B,C,D,E)四个连接。为了简化问题,我们只考虑嵌套连接。我们使用的规则是“使用最低成本的连接”。
- 我们从五张表中任意一个开始(例如,从 A 开始)
- 计算与 A 的每一个连接的成本(A 作为内关系或外关系)
- 发现 A JOIN B 是最低成本
- 然后计算与 A JOIN B 结果关联的每一个连接的成本(A JOIN B 作为内关系或外关系)
- 找到 (A JOIN B) JOIN C 是最低成本
- 然后计算与 (A JOIN B) JOIN C 结果关联的每一个连接的成本…
- ….
- 最后,找到计划 (((A JOIN B) JOIN C) JOIN D) JOIN E)
由于我们是随机从 A 开始,因此也可以为 B、C、D 和 E 应用相同的算法。最后,我们找到了拥有最低成本的计划。
人们给使用这种方法的算法取了一个名字:最近邻居算法。
我不会展开阐述,只说结论,通过良好的建模和 N*log(N) 的排序,该问题可以很容易解决。这个算法的时间复杂度是 O(N*log(N)),相比而言,完全动态规划算法的时间复杂度是 O(3N)。如果你有一个 20 个连接的大查询,这意味着 26 比 3 486 784 401,这个差距非常巨大!
这个算法的问题是,我们假设如果能够一直找到两个表直接的最好连接,并且在此基础上增加新的连接,依然能够保持最好的成本。但是:
- 在 A、B、C 三者之间,即便 A JOIN B 给出最好成本
- (A JOIN C) JOIN B 依然可能比 (A JOIN B) JOIN C 还要好
为改进结果,你可以使用不同规则多次运行贪心算法,保留最好的计划。
其它算法
[如果你已经厌倦了算法,直接跳到下一部分就好了。下面我将要介绍的内容与本文其它部分没有太大关系。]
找到最佳解决方案一直是计算机科学家的热门研究方向。他们试图为更多精确的问题或模式找到更好的解决方案。例如:
- 如果查询是星连接(就是多个连接查询的中心位置),有些数据库会使用特殊的算法
- 如果查询是并行的,有些数据库也会使用特殊的算法
- …
另外的算法同样有被研究,以便取代大查询的动态规划。贪心算法属于一个称为启发式算法的更大的算法家族。贪心算法遵循一个规则(或启发),持有上一步发现的解决方案,在当前步骤将这个解决方案“追加”以便获得新的解决方案。有些算法则是遵循规则,每一步都会应用规则,但是不会始终保存上一步找到的最佳解决方案。这种算法被称为启发式算法。
例如,遗传算法依照规则,但是并不始终保存上一步的最好结果:
- 一个能够表示全查询计划的可能解决方案
- 在每一步不只保存一个,而是保存 P 个解决方案
- 0) P 个查询计划是随机创建的
- 1) 只有最好成本的计划被保留
- 2) 这些最好的计划混合起来,创建 P 个新的计划
- 3) 这些 P 个新计划中的某些被随机改变
- 4) 重复 1,2,3 步 T 次
- 5) 在最后一次循环之后,找到 P 个计划的最佳计划
循环越多,你能获得的计划就会越好。
听起来就像魔法一样?不,这是自然法则:适者生存!
仅供参考,遗传算法在 PostgreSQL 有实现,但是我不确定是不是默认使用了该算法。
数据库还使用了一些别的启发式算法,例如模拟退火算法、迭代改进算法、两阶段优化… 但是我不确定这些算法是不是已经应用在企业级数据库中,还是仅仅出现在研究型的数据库中。
更多信息可以阅读下面的论文,这篇论文列举了更多算法:Review of Algorithms for the Join Ordering Problem in Database Query Optimization。
真实的优化器
[你可以直接跳到后面的章节,这部分也不是非常重要]
但是,我们啰嗦了半天,都是理论上的。因为我是一个开发人员,不是研究学者,我喜欢具体的例子。
下面看 SQLite 优化器是如何工作的。这是一个轻量级数据库,使用了基于额外规则的贪心算法的简单优化,用于限定可能数:
- SQLite 从不重新排序 CROSS JOIN 运算符中的表
- 连接使用嵌套连接实现
- 外连接始终按照出现的顺序
- …
- 在 3.8.0 之前的版本,SQLite 使用“最近邻居”贪心算法检索最佳查询计划
等一下… 我们已经见到了这个算法了!真巧!
- 从 3.8.0 (2015 年发布)开始,SQLite 使用“N 个最近邻居”贪心算法检索最佳查询计划
我们看看另外的优化器是怎么工作的。IBM DB2 和其它所有企业级数据库一样,我将介绍 DB2,因为这是我转换到大数据之前唯一真正使用过的数据库。
如果我们阅读官方文档,我们就会发现 DB2 优化器允许你使用 7 个不同级别的优化:
- 使用贪心算法处理连接
- 0 – 最小优化,使用索引扫描和嵌套循环连接,避免某些查询重写
- 1 – 低优化
- 2 – 全优化
- 使用动态规划处理连接
- 3 – 中度优化,粗略近似
- 5 – 全优化,使用基于启发式算法的所有技术
- 7 – 全优化,与 5 类似,但是不使用启发式算法
- 9 – 最大优化,不遗余力考虑所有可能的连接顺序,包括笛卡尔积。
我们可以发现,DB2 使用了贪心算法和动态规划。当然,他们不会告诉你启发式算法的细节,因为查询优化器是一个数据库强大所在。
仅供参考,默认级别是 5。优化器默认使用下面的特性:
- 使用全部可用的统计,包括快速统计值和分位数统计
- 应用所有查询重写规则(包括物化查询表路由),除了仅适用于少数情况的计算密集型规则
- 使用动态规划算法连接枚举,包括:
- 限制使用内关系组合
- 限制针对星模式使用笛卡尔积查询表
- 考虑大范围访问函数,包括列举预取(我们会在后文介绍这个词的含义),索引 AND(针对索引的特殊操作)和物化查询表路由
默认的,DB2 针对连接排序,使用有限制的启发式动态规划。
其它条件(GROUP BY, DISTINCT…)则使用简单规则处理。
查询计划缓存
由于创建计划要花费一定时间,大部分数据库都会将计划保存到查询计划缓存。这是一个复杂的话题,因为数据库需要知道什么时候更新过时的计划。其思路是,使用一个阈值,如果表的统计数据发生的改变超过了阈值,那么有关这个表的查询计划都会从缓存清除。
查询执行器
在这一阶段,我们有了经过优化的执行计划。这个计划会被编译成可执行代码。然后,如果有足够的资源(内存、CPU),查询执行器就会执行这个计划。计划中的运算符(JOIN, SORT BY …)可以顺序或并发执行,这取决于执行器。为了获取和写入数据,查询执行器与数据管理器进行交互,下一章我们就将介绍数据管理器。
